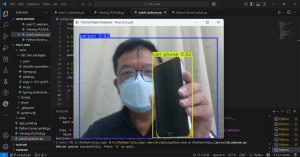
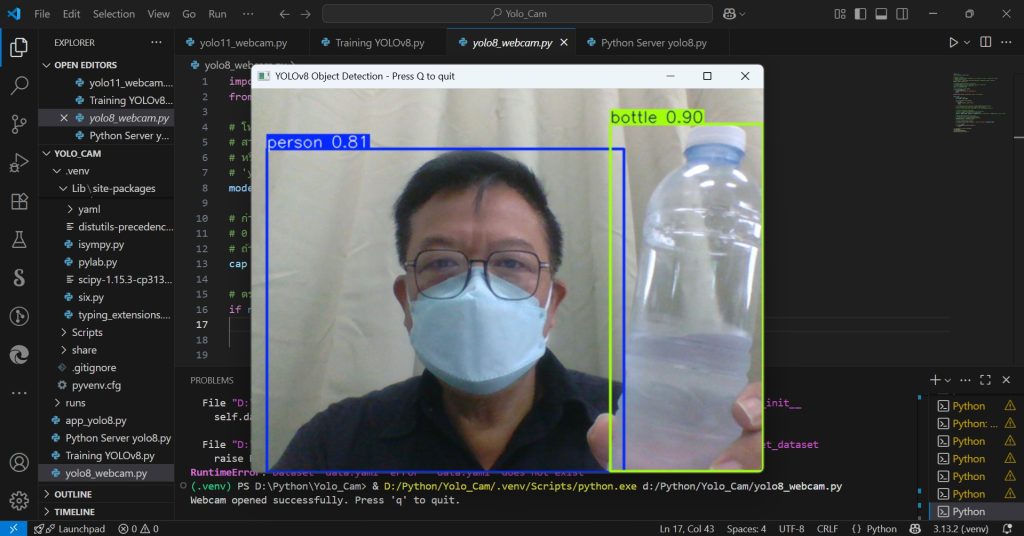
การทำ AI Training YOLOv8 ด้วย Python
ในการ Training YOLOv8 ด้วย Python นั้น จะต้องทำตามขั้นตอนหลักๆ ดังนี้:
- ติดตั้ง Ultralytics YOLOv8: นี่คือไลบรารีอย่างเป็นทางการที่ง่ายที่สุดในการใช้งาน YOLOv8
- เตรียม Dataset: คุณจะต้องมีข้อมูลรูปภาพพร้อม Annotation (Bounding Box และ Class) ในรูปแบบที่ YOLOv8 เข้าใจ (COCO หรือ YOLO format)
- สร้างหรือแก้ไขไฟล์
dataset.yaml: ไฟล์นี้จะระบุพาธของข้อมูล, ชื่อคลาสต่างๆ - เขียนโค้ด Python สำหรับ Training: ใช้โค้ดง่ายๆ ไม่กี่บรรทัดจากไลบรารี Ultralytics
อธิบายแต่ละขั้นตอนพร้อมโค้ดตัวอย่าง:
ขั้นตอนที่ 1: ติดตั้ง Ultralytics YOLOv8
เปิด Terminal หรือ Anaconda Prompt แล้วรันคำสั่งนี้:
Bash
pip install ultralytics
ขั้นตอนที่ 2: เตรียม Dataset
Dataset ของคุณควรจะอยู่ในโครงสร้างแบบนี้ (YOLO Format) ถ้าคุณมีในรูปแบบ COCO แล้ว คุณอาจจะต้องแปลงก่อน ซึ่งมีเครื่องมือหลายอย่างช่วยได้ หรือบางครั้ง Ultralytics ก็รองรับการโหลด COCO โดยตรงครับ
your_dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── image_val1.jpg
│ │ └── ...
│ └── test/ (Optional, for final evaluation)
│ ├── image_test1.jpg
│ └── ...
└── labels/
├── train/
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
├── val/
│ ├── image_val1.txt
│ └── ...
└── test/ (Optional)
├── image_test1.txt
└── ...
ตัวอย่างไฟล์ image1.txt (label file):
แต่ละบรรทัดในไฟล์ .txt จะแทนหนึ่ง Object: class_id center_x center_y width height
0 0.5 0.5 0.2 0.3 # Class 0, bounding box normalized coordinates
1 0.2 0.8 0.1 0.15 # Class 1, bounding box normalized coordinates
class_id: เลข ID ของคลาส (เริ่มต้นที่ 0)center_x, center_y, width, height: ค่าพิกัดและขนาดของ Bounding Box ที่ถูก Normalize (หารด้วยความกว้าง/สูงของรูปภาพ) ค่าจะอยู่ระหว่าง 0 ถึง 1
ขั้นตอนที่ 3: สร้างหรือแก้ไขไฟล์ dataset.yaml
สร้างไฟล์ชื่อ data.yaml (หรือชื่ออะไรก็ได้ที่คุณต้องการ) ในโฟลเดอร์เดียวกับสคริปต์ Python ของคุณ หรือในโฟลเดอร์ของ Dataset ก็ได้
ตัวอย่าง data.yaml:
YAML
# Path to your dataset root directory
path: ../your_dataset/ # หรือ C:/Users/YourUser/Desktop/your_dataset/ ถ้าคุณระบุพาธแบบเต็ม
# Train and validation image paths
train: images/train # path relative to 'path'
val: images/val # path relative to 'path'
# test: images/test # Uncomment if you have a test set
# Class names
names:
0: class_name_0
1: class_name_1
2: class_name_2
# ... เพิ่มตามจำนวนคลาสของคุณ
สำคัญ:
path: เป็น root directory ของ dataset ของคุณtrain,val,test: เป็นพาธแบบ Relative จากpathไปยังโฟลเดอร์รูปภาพของส่วน Train, Val, Testnames: ลิสต์ชื่อคลาสของคุณ โดยที่ Key (0, 1, 2, …) คือclass_idและ Value คือชื่อคลาส
ขั้นตอนที่ 4: เขียนโค้ด Python สำหรับ Training
นี่คือโค้ด Python สำหรับ Training YOLOv8:
Python
from ultralytics import YOLO
# 1. โหลดโมเดล (เลือกโมเดลที่ต้องการ)
# คุณสามารถเลือกโมเดลที่ pre-trained มาแล้ว (เช่น 'yolov8n.pt' สำหรับ nano version)
# หรือจะเริ่มต้นจากโมเดลเปล่า (randomly initialized weights) ก็ได้
# ถ้าเริ่มต้นจากโมเดลเปล่า: model = YOLO('yolov8n.yaml')
model = YOLO('yolov8n.pt') # ใช้ yolov8n.pt (nano) ที่ pre-trained แล้ว
# 2. เริ่มต้น Training
# 'data' ชี้ไปยังไฟล์ dataset.yaml
# 'epochs' คือจำนวนรอบที่โมเดลจะเรียนรู้จากข้อมูลทั้งหมด
# 'imgsz' คือขนาดของภาพที่โมเดลจะใช้ในการ Training (รูปภาพจะถูกปรับขนาดให้เท่ากัน)
# 'batch' คือขนาดของ batch size
results = model.train(data='data.yaml', epochs=100, imgsz=640, batch=16)
# 3. (Optional) ประเมินผลโมเดลบนชุดข้อมูล validation
# results = model.val()
# 4. (Optional) ทำนายผลด้วยโมเดลที่ train แล้ว
# results = model('path/to/your/image.jpg')
# 5. (Optional) ส่งออกโมเดลในรูปแบบต่างๆ (เช่น ONNX, OpenVINO, TFLite)
# model.export(format='onnx')
คำอธิบายพารามิเตอร์ที่สำคัญใน model.train():
data: (Required) พาธไปยังไฟล์data.yamlที่คุณสร้างไว้epochs: (Required) จำนวน Epochs ในการ Training. จำนวนที่มากขึ้นอาจจะให้ผลลัพธ์ที่ดีขึ้นแต่ก็ใช้เวลานานขึ้นและเสี่ยงต่อ Overfittingimgsz: (Optional, default=640) ขนาดของรูปภาพที่ใช้ในการ Training. รูปภาพจะถูกปรับขนาดเป็นimgsz x imgszก่อนเข้าสู่โมเดลbatch: (Optional, default=16) Batch size. จำนวนรูปภาพที่จะถูกประมวลผลพร้อมกันในหนึ่งรอบการ Iteration. ขนาด Batch ที่ใหญ่ขึ้นอาจจะทำให้ Training เร็วขึ้นแต่ก็ใช้ RAM GPU เยอะขึ้นname: (Optional) ชื่อของโปรเจกต์ (โฟลเดอร์ที่ผลลัพธ์จะถูกบันทึก)project: (Optional) โฟลเดอร์หลักที่จะเก็บโปรเจกต์ต่างๆdevice: (Optional) ระบุอุปกรณ์ที่จะใช้ Training (e.g.,0สำหรับ GPU ตัวแรก,0,1สำหรับ GPU สองตัว,cpuสำหรับ CPU)patience: (Optional) จำนวน Epochs ที่ไม่มีการปรับปรุงค่า validation metric (เช่น mAP) ก่อนที่การ Training จะหยุดอัตโนมัติ (Early Stopping)optimizer: (Optional) ประเภทของ Optimizer (เช่น ‘Adam’, ‘SGD’, ‘RMSProp’)lr0: (Optional) Initial learning ratelrf: (Optional) Final learning rate- และพารามิเตอร์อื่นๆ อีกมากมายสำหรับ Hyperparameter Tuning ดูได้จาก Ultralytics Docs
ผลลัพธ์การ Training:
เมื่อคุณรันโค้ดนี้ Ultralytics จะสร้างโฟลเดอร์ runs/detect/trainX (โดยที่ X คือเลขรัน) ซึ่งจะเก็บ:
weights/best.pt: โมเดลที่ดีที่สุดที่ถูก Train มาแล้วweights/last.pt: โมเดลล่าสุดresults.csv: ค่า Metric ต่างๆ ในแต่ละ Epochconfusion_matrix.png,F1_curve.png,P_curve.png,R_curve.png: กราฟต่างๆ ที่ช่วยในการวิเคราะห์ผลval_batchX_pred.jpg: รูปภาพตัวอย่างพร้อม Bounding Box ที่ทำนายบนชุดข้อมูล Validation
ตัวอย่างการใช้งานโมเดลที่ Train แล้ว:
หลังจาก Training เสร็จ คุณสามารถโหลดโมเดล best.pt หรือ last.pt เพื่อใช้งานได้:
Python
from ultralytics import YOLO
# โหลดโมเดลที่ Train มาแล้ว
model = YOLO('runs/detect/train/weights/best.pt') # หรือ 'runs/detect/train/weights/last.pt'
# ทำนายบนรูปภาพเดียว
results = model('path/to/your/image.jpg')
# ทำนายบนโฟลเดอร์ของรูปภาพ
# results = model('path/to/your/image_folder/')
# แสดงผลลัพธ์ (อาจจะเป็นรูปภาพพร้อม bounding box, หรือ object list)
for r in results:
im_bgr = r.plot() # plot returns an image with bounding boxes and labels in BGR format
# แสดงรูปภาพด้วย OpenCV หรือบันทึกลงไฟล์
# import cv2
# cv2.imshow('Result', im_bgr)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# cv2.imwrite('output_image.jpg', im_bgr)
print(f"Boxes: {r.boxes}") # Bounding Boxes, Classes, Scores
print(f"Masks: {r.masks}") # Segmentation Masks (if using segmentation model)
print(f"Keypoints: {r.keypoints}") # Keypoints (if using pose estimation model)
print(f"Probabilities: {r.probs}") # Classification Probabilities (if using classification model)
สรุปขั้นตอนการทำงาน:
- เตรียมสภาพแวดล้อม: ติดตั้ง Python, pip, และ
ultralytics - รวบรวมข้อมูล: รูปภาพและ Annotation
- จัดโครงสร้าง Dataset: ให้เป็นไปตามที่ YOLOv8 กำหนด (โดยเฉพาะ YOLO format สำหรับ labels)
- สร้าง
data.yaml: กำหนดพาธของข้อมูลและชื่อคลาส - เขียนโค้ด Python: ใช้
from ultralytics import YOLOและmodel.train()เพื่อเริ่มต้น Training - รันโค้ด: รอให้โมเดล Train จนเสร็จ
- ประเมินและใช้งาน: โหลดโมเดลที่ Train แล้วมาใช้งานหรือประเมินผล
การ Training YOLOv8 ค่อนข้างตรงไปตรงมาด้วยไลบรารี Ultralytics ครับ ขอให้สนุกกับการพัฒนาโมเดลของคุณ!